
たき(@tetsuzawa)です。
一年ほど前に内定者インターンの業務でパフォーマンスチューニングに取り組む機会があり、サーバーの負荷の約50%減らすことに成功しました。パフォーマンスチューニングを行うにあたってはBrendan Greggさんのブログを大いに参考にしてます。今回は先程のブログで紹介されていたいくつかの方法論と、自分が実際にやって大事だと感じた3つのフェーズについて書いていきます。
パフォーマンスチューニングとは
パフォーマンスチューニングとはシステムのボトルネックを解消していく作業です。
システムのボトルネックを適切に解消するには
現状把握
解析
改善
の3つのフェーズを意識するのが大事だと考えています。
良い改善を行うためには適切な解析を行うことが重要です。
そのためには改善対象のシステムの現状を把握しておく必要があります。
しかし、どのように作業を進めれば良いのか迷う方も多いでしょう。
この記事では、方法論を使用した進め方について共有します。
方法論 とはBrendan Greggさんが紹介しているパフォーマンス分析の手順をまとめたもので、現在20種類以上公開されています。
で今回はその中のいくつかの方法論を使って、3つのフェーズを進める方法について説明していきます。
1.現状把握フェーズ
パフォーマンスチューニングではまず始めに現状を把握することが重要です。
現状を把握する目的は先入観や勘違い、推測を無くすことです。
現状を把握するための方法論としてProblem Statement Methodというものがあります。
Problem Statement Method は以下の質問に答えることで何のために何を改善したいのかをはっきりさせるための方法論です。
まずはこの質問に答えてパフォーマンスチューニングの目的をはっきりとさせましょう。
What makes you think there is a performance problem?
Has this system ever performed well?
What has changed recently? (Software? Hardware? Load?)
Can the performance degradation be expressed in terms of latency or run time?
Does the problem affect other people or applications (or is it just you)?
What is the environment? Software, hardware, instance types? Versions? Configuration?
以下は私の事例の回答です。
x86_64からaarch64 (Graviton) に移行したらResponse time・Throughputが40%悪化したから
x86_64はaarch64 (Graviton)より速かった
CPUのアーキテクチャ(x86_64 -> aarch64)
はい
レスポンスを返すのが遅くなってるだけ
↓
software: scala2.11.12, java8 (amazon-corretto1.8.0), tomcat8, amazon linux 2 (amzn2-ami-hvm-2.0.20210525.0-arm64-gp2)
hardware: aarch64, graviton
instance type: c6g.4xlarge
これらに加えて対象のシステムについて深く理解することも重要です。
システムの運用のされ方、内容、実装などについて理解していることは目的達成の近道になります(実体験)。
現状把握は解像度が高いに越したことは無いです。時間と気合を必要とするかもしれませんが「急がば回れ」の気持ちで頑張りましょう。
2.解析フェーズ
現状を把握することができたら解析フェーズに移ります。
その前に...ボトルネックはどこに現れるのか
具体的な解析方法に入る前にボトルネックがどこに現れるのかについて説明します。
下記の図はOSの簡易的なモデルを示しています。
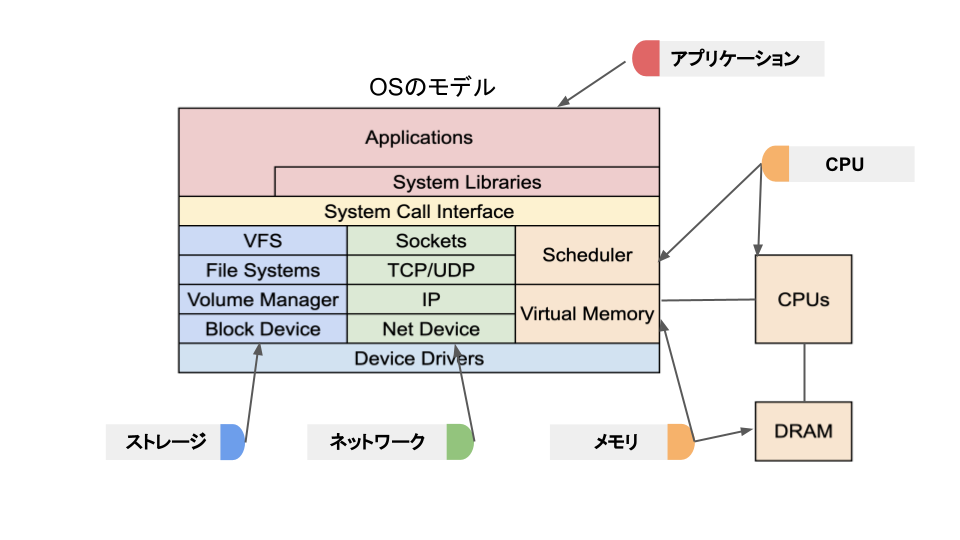
この図ではモデルをアプリケーションと4つのリソース(CPU、メモリ、ストレージ、ネットワーク)に大別しています。
このような分け方にしているのには意図があります。
アプリケーションはOSのSystem Call Interfaceを通じてリソースを使用することで動いています。
つまり、アプリケーションのパフォーマンスにボトルネックが生じてるとき、実際にはリソースにボトルネックが存在することを示しています。
リソースを4つに分けているのはこれらのどれかにボトルネックが存在することが多いためです。
(AWSでも4つのリソースに特化したインスタンスタイプが用意されているのはおそらくこのような背景があるためだと思っています https://aws.amazon.com/jp/ec2/instance-types/ )
USE MethodとTSA Method
解析フェーズでは複数の視点で解析を進めることが重要です。
というのも、一つの解析結果に注目しすぎて不適切な解析をしているのに気づけないことが往々にしてあるからです。(これも実体験)
そこで今回はUSE MethodとTSA Methodという2つの方法論を紹介します。
それぞれUSE Methodはリソース指向、TSA Methodはスレッド指向という点で別の視点を持つので、両方使うことで効果的な解析を行うことができます。
USE Method
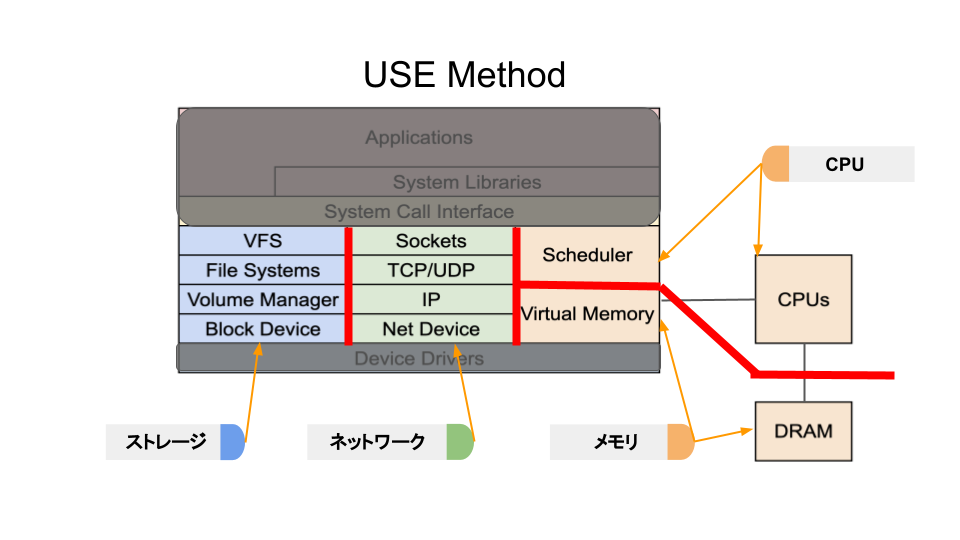
USE Methodはリソース指向の方法論です。
各リソースをはっきりと切り分けてUSEの視点で問題を調査することでリソースのボトルネックを見つけることができます。
USEとはUtilization(使用率)・Saturation(飽和度)・Error(エラー)のことです。
下記はUSEの一例です
Utilization
CPUやメモリの使用率が高すぎないか
Saturation
CPU使用率が一瞬でも100%になっていないか
Run queueがCPUのコア数を超えていないか
スワップが発生していないか
Error
メモリ確保失敗が起きていないか
ネットワーク衝突
USE Methodのメリット・デメリット
USE Methodにはリソースに着目することで効率的に問題の切り分けができるというメリットがあります。
一方で、リソース問題の起因となるアプリケーションについては解析できないことがデメリットとして挙げられます。
USE Methodのやり方
USE MethodではリソースごとにUSEを調べるコマンドのチェックリストが公開されてます。(https://www.brendangregg.com/USEmethod/use-linux.html)
基本的にはこのチェックリストに従うのをおすすめします。
しかし中にはperfを駆使して解析する項目も含まれているので、深入りして時間を使いすぎないよう注意が必要です。
USE Methodの計測項目に固執するよりも後述するTSA Methodや他の方法論を試すほうが全体として良い場合もあります。
最初はNetflixのTechblog(https://netflixtechblog.com/linux-performance-analysis-in-60-000-milliseconds-accc10403c55 )で紹介されている以下のコマンド群で代替するのも有効でしょう。
uptime
dmesg | tail
vmstat 1
mpstat -P ALL 1
pidstat 1
iostat -xz 1
free -m
sar -n DEV 1
sar -n TCP,ETCP 1
top
各コマンドの使い方については省略するので元記事を参照してください。
コマンドを実行することができたら結果を見やすいように記録しておくことをおすすめします。
また、USE Methodの考え方はスレッドプールやファイルディスクリプタなどのソフトウェアリソースにも適用できるので、システムにリソースとみなせる項目がないか探してみるのも良いと思います。
※ チェックリストのコマンドをモニタリングツールで代用する案もありますが、おすすめはしません。なぜならメトリクスが時間平均されていてSaturationに気づけなかったり、そもそもメトリクス化が難しい項目があるためです。
TSA Method
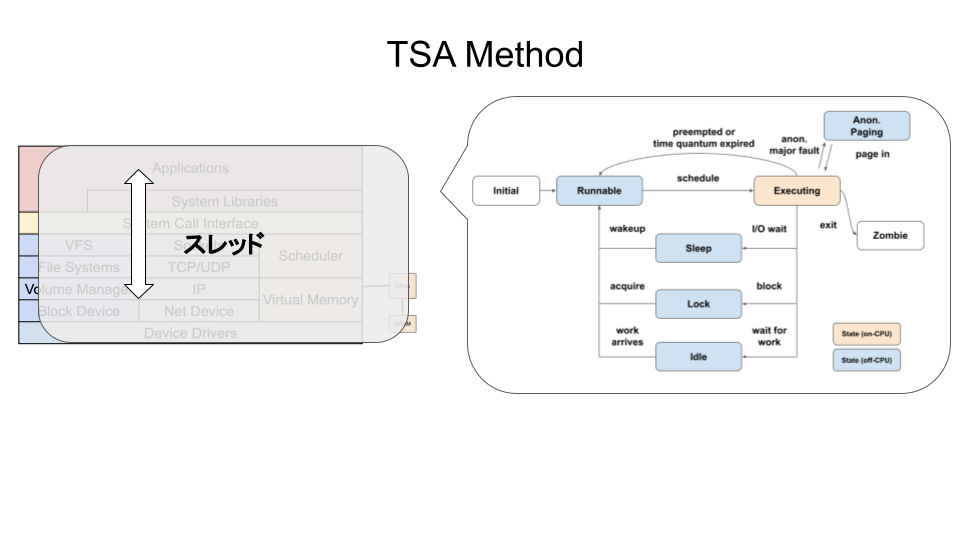
TSA Method (Thread State Analysis Method) はスレッド指向の方法論です。
アプリケーションがどのように時間を使っているのか解析することができます。
具体的には次のステップに従って解析を進めます。
解析対象のスレッドについて各状態(State)にいる合計時間を測定
合計時間が長い状態から順に適切なツールで解析
TSA Methodのメリット・デメリット
TSA Methodのメリットはあるスレッドがどこの処理で時間を費やしているのかがわかることです。
一方で、TSA Methodではリソースに問題があるかどうかはわかりません。
つまり、USE Methodとは相補的な関係にあるということです。
TSA Methodのやり方
上の図ではUNIXプロセスの状態遷移に基づいて状態を6つに分けています。
しかし残念なことに、これらの状態を調べるためのチェックリストはまだ公開されてません。
そこで、今回は6つの状態をさらにon-CPUとoff-CPUの2つに分けて解析する方法をご紹介します。
具体的な解析方法に入る前にon-CPUとoff-CPUについて知る必要があるでしょう。
on-CPUとは、そのままの意味でスレッドがCPUを使用している状態です。
off-CPUとは、ネットワーク、ディスクI/O、マルチスレッドのブロッキング等によってスレッドが待機状態にあることを指します。
スレッドは必ずon-CPUかoff-CPUどちらかの状態であるため、2つの状態を解析することで、消費される時間の100%を把握することができます。
上記の6つ状態は次のように分類することができます。
on-CPU
Executing(実行)
off-CPU
Runnable(実行可能)
Anonymous Paging(匿名ページング)
Sleep(スリープ)
Lock(ロック)
Idle(アイドル)
さて、on-CPUとoff-CPUの状態を解析するためには当然それらに対応するプロファイラーが必要です。
今回はJVM用のサンプリング型プロファイラーである async-profiler を例として使います。
async-profilerを使うのはcpuプロファイリングとwall-clock プロファイリングを行うことができるためです。
wall-clock プロファイリングとはCPUの状態に限らず一定間隔でサンプリングを行う手法です。
CPUプロファイリングでは次の図のようにon-CPUの状態しか解析できません。
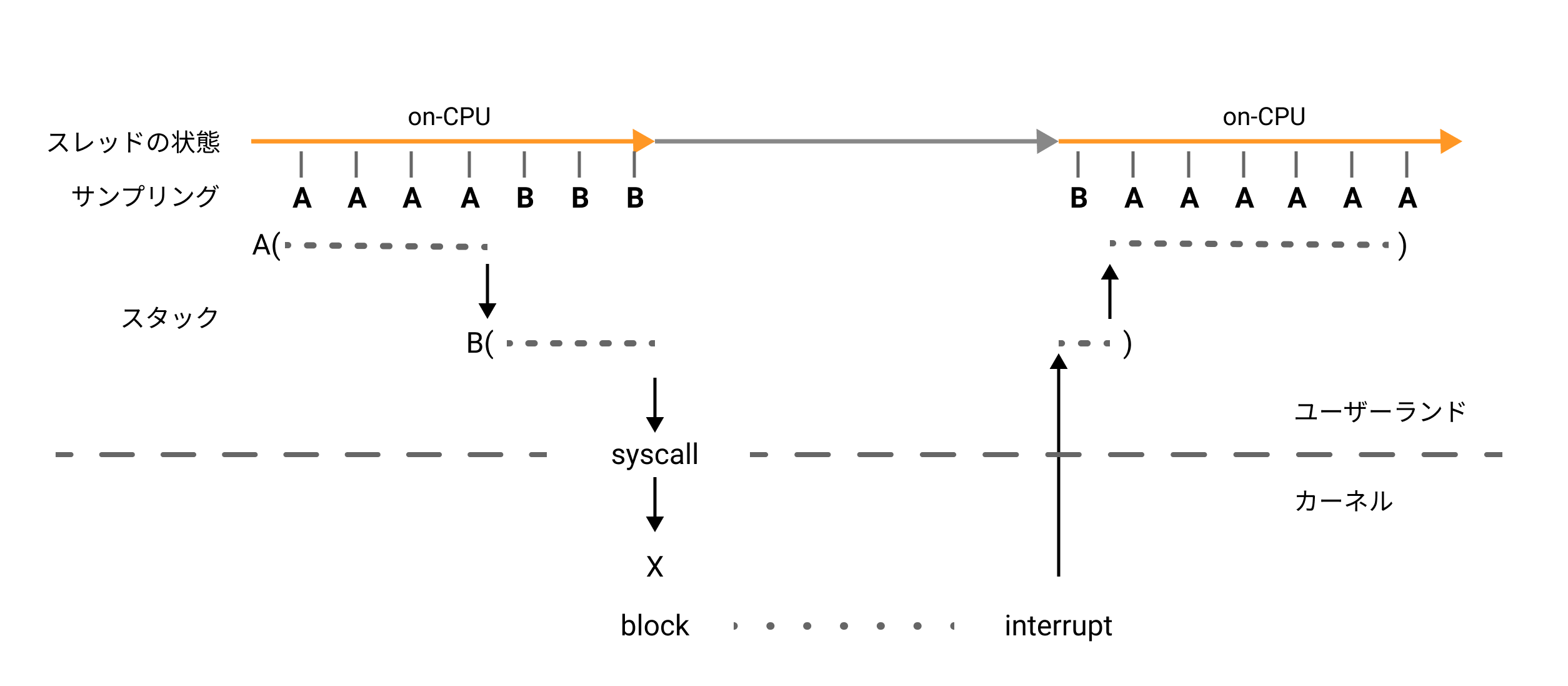
一方で、wall-clockプロファイリングでは図のようにoff-CPUもサンプリングします。
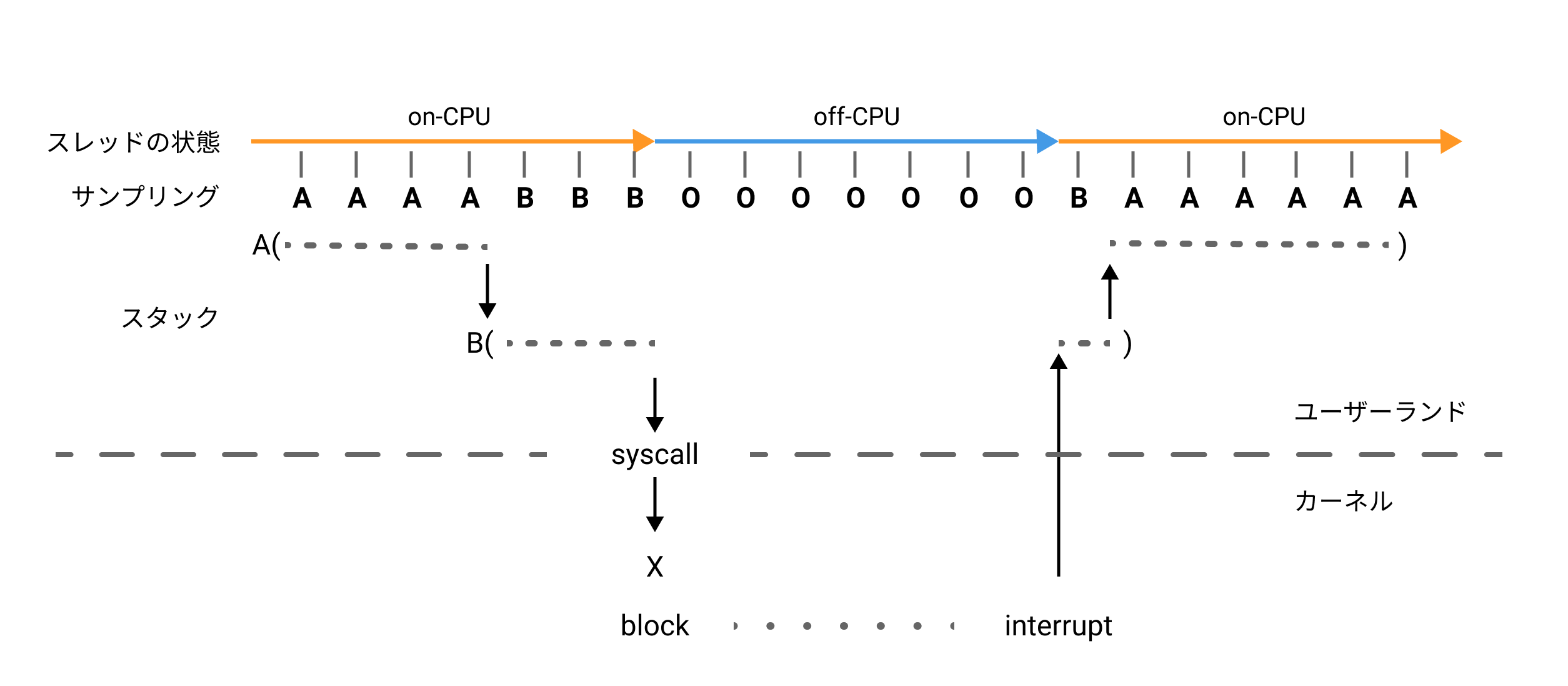
したがって、2つのプロファイリング結果を比較することで各状態の合計時間を求めることができます。
実行方法は非常にシンプルで次のコマンドを叩くだけです。
# CPUプロファイリングの場合
./profiler.sh -e cpu -d 60 -t -i 1ms -f “cpu_flamegraph.html" <JavaのPID>
# wall-clockプロファイリングの場合
./profiler.sh -e wall -d 60 -t -i 1ms -f "/wall_flamegraph.html" <JavaのPID>
重要なのは -t でスレッドごとの解析をすることと、-i でサンプリング間隔を揃えることです。
デモ用のシステム(https://github.com/tetsuzawa/tsa-method-demo-jvm )に対して実行すると次のようなフレームグラフが生成されます。
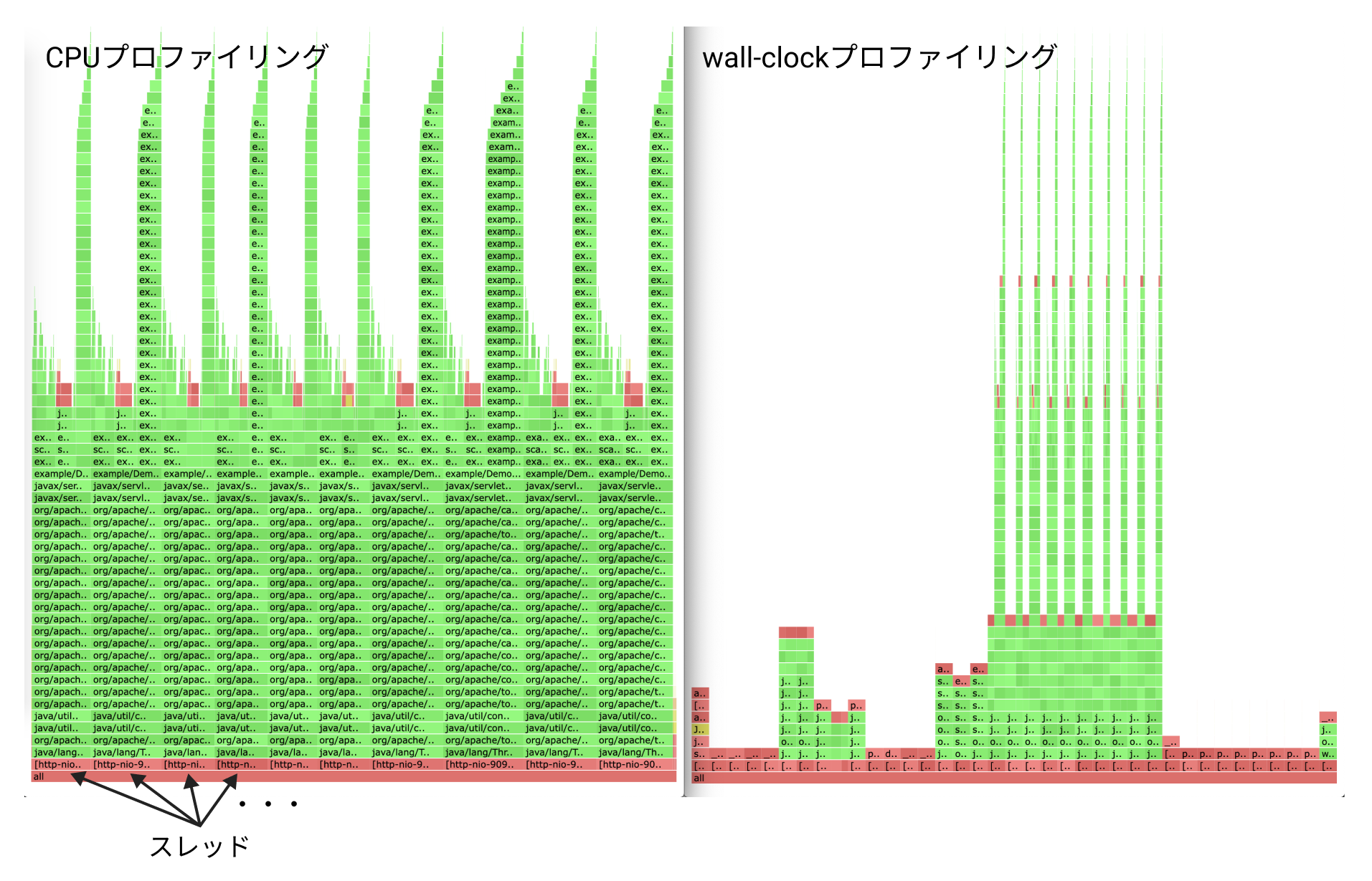
左側がCPUプロファイリング、右側がwall-clockプロファイリングです。
※ wall-clockプロファイリングの場合、待ち状態にあるスレッドもサンプリングされるため、図のようにぱっと見全く異なるフレームグラフが生成されることがあります。
さて、まずはTSA Methodに従うために一つのスレッドに注目して比較を行います。目的のスレッドをクリックして拡大すると下の図のような表示に変わります。
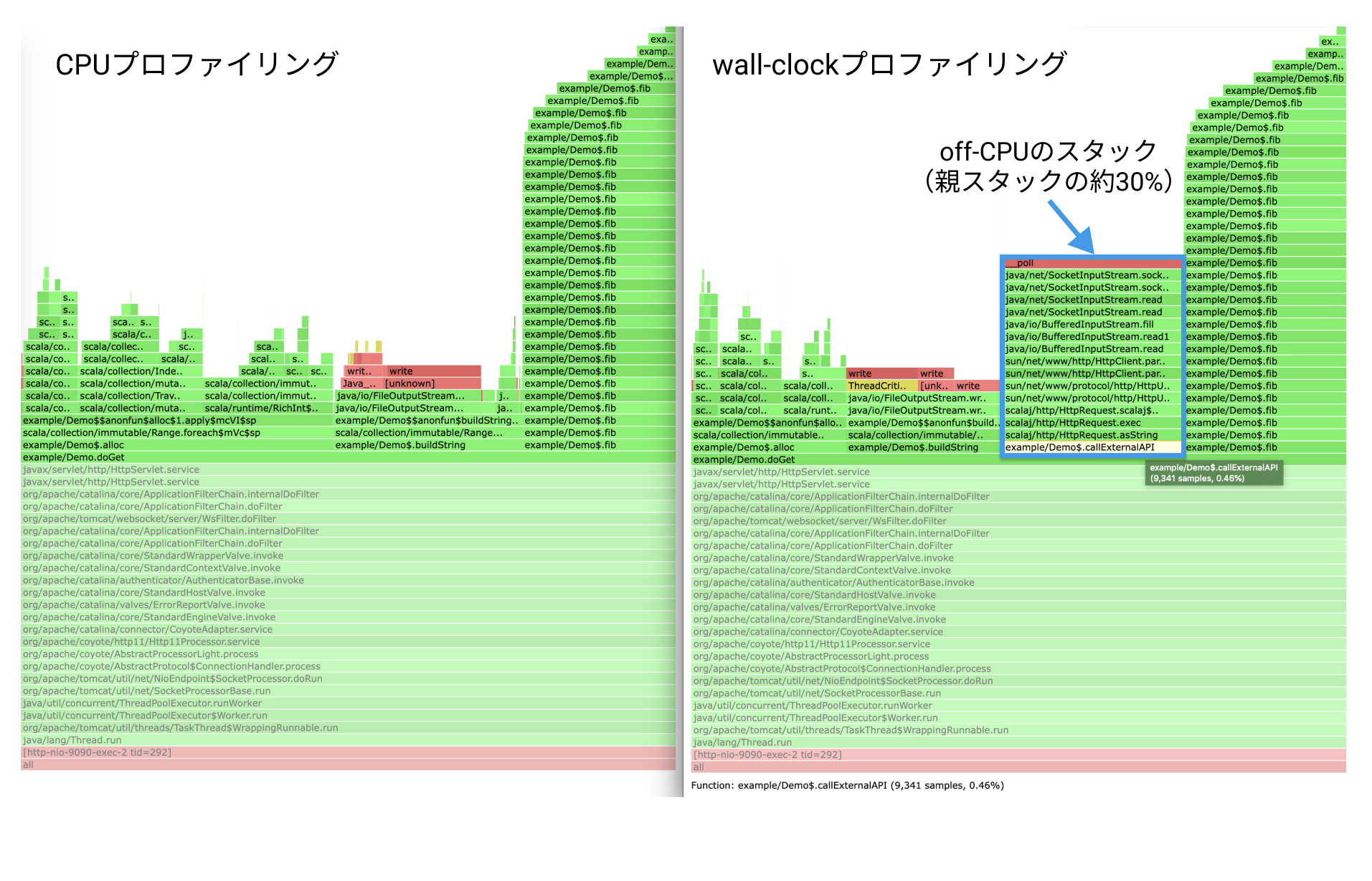
さて、2つの図を見比べて見ましょう。
wall-clockプロファイリングにはCPUプロファイリングに無いスタック(図のcallExternalAPI)があることがわかります。これがoff-CPUのスタックです。
このスタックのサンプリング数は親スタックの約30%であるため、on-CPUの時間の方が長いことがわかりました。
次にon-CPUの状態について詳しく解析を行いますが、この例では追加のツールは必要ありません。なぜなら実行時間の長い関数がフレームグラフから既にわかっているからです。あとは関数内のコードを読めば解析として十分でしょう。
長くなりましたがTSA Methodのやり方は以上になります。
(蛇足ですが、on-CPUとoff-CPUの見分けをつきやすくしたHot/Cold FlameGraphを生成するPR をasync-profilerに出しています。ご興味のある方はダウンロードしてみてください。)
3.改善フェーズ
最後に改善フェーズに移ります。
改善フェーズでは目的と解析結果に合った施策を打つ必要があります。
例えば、CPU使用率を下げることが目的ならon-CPUで時間を消費している関数を改善すべきでしょう。レスポンスタイムを短くするのが目的ならwall-clockプロファイリングでボトルネックとなっている関数を見つけて改善すべきです。もし、USE Methodでストレージやネットワークに問題があることがわかったならインスタンスタイプを変更するのも一つの手です。
重要なのは施策を実行したあとに現状把握と解析を行って差分を把握することです。
したがって、ここでは私たちが行ってきた施策を2つ例として紹介します。
AWS Graviton2の導入
1つ目の施策はAWS Graviton2の導入です。
目的はシステムのコスト削減です。
導入では公式で用意されているaws-graviton-getting-started というレポジトリをもとに以下の施策を行いました。
ビルド・ランタイムにAmazon Correttoを使用
JVM Option の追加(階層コンパイラの使用やコードキャッシュサイズの指定)
kernel-ngの利用
結果としてはパフォーマンス向上につながりませんでした。
理由については、シングルスレッド性能を必要とするワークロードがGraviton 2にマッチしなかったのだろうと考えています。
データ構造・アルゴリズムの変更
2つ目の施策はデータ構造の変更です。
目的はシステムのコスト削減です。
この施策ではCPU使用率を下げることでインスタンス台数が減ることを狙いました。
やったことはScalaで書かれた次のコードを変更しました。
val checkList: Seq[Map[String, String]] = Seq(
Map("a" -> "a1", "b"-> "b1"),
Map("a" -> "a2", "b"-> "b2"),
Map("a" -> "a3", "b"-> "b3"),
...
)
def exists(target: String) =
checkList.exists(e => target == v.get("a") || target == e.get("b") || target == e.get("b") + "suffix")
このコードではcheckListとしてMapを要素に持ち、exists関数内で文字列結合を行っています。
変更後のコードはこちらです。
case class Elem(a: String, b: String, bs: String)
val checkList: Seq[Elem] = Seq(
Elem("a1", "b1", "b1" + "suffix"),
Elem("a2", "b2", "b2" + "suffix"),
Elem("a3", "b3", "b3" + "suffix"),
...
)
def exists(target: String) =
checkList.exists(e => target == e.a || target == e.b || target == e.bs)
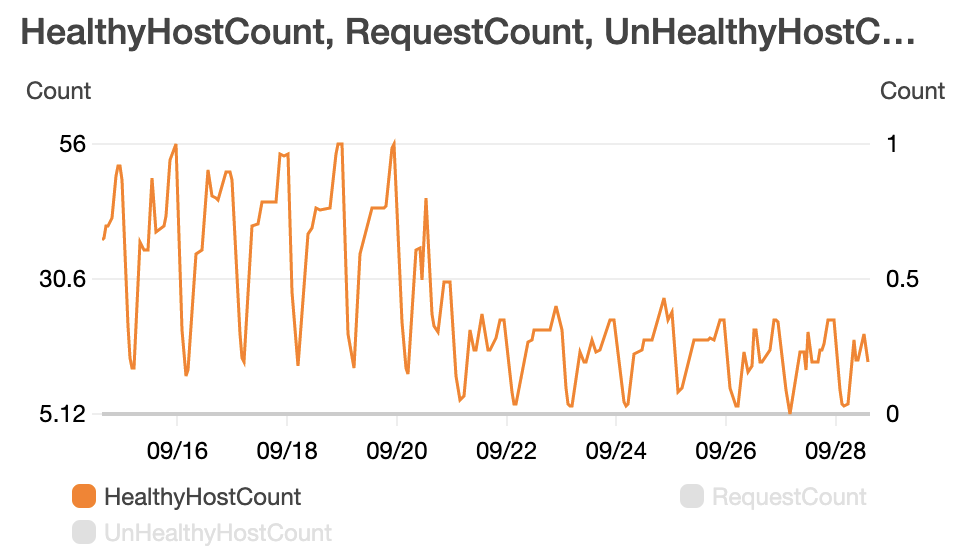
適切なデータ構造に置き換えるだけの小さい変更ですが、結果的にインスタンス台数を50%ほど減らすことができました。
まとめ
この記事では方法論を駆使しながら現状把握・解析・改善の3つのフェーズでパフォーマンスチューニングを行う方法について書きました。
実はこの記事の時系列は
Graviton2導入失敗 ----> 原因調査の過程で方法論を知る -------------> 別タスクでシステムを理解 -> インスタンス台数約50%削減
のようになっていました。
改善に成功したのはシステムを理解してすぐだったので、一番大事なのは現状把握ではないかと考えています。
また、お気づきの方もいらっしゃると思いますが、これらはISUCON参加記などでもよく見かける流れです。
紹介した3つのフェーズのサイクルに慣れればかなり効率的にパフォーマンスを改善することができると思います。